本文共 5028 字,大约阅读时间需要 16 分钟。
背景
日志无处不在,它作为记录世间万物变化的载体,在运维、研发、运营、安全、BI、审计等领域有着广泛的应用场景。

是日志类数据的一站式服务平台,其核心组件 LogHub 凭借着高吞吐、低延迟、可自动伸缩等特性,逐渐成为大数据处理领域特别是实时数据处理场景下的基础设施。那些运行在 、、 等大数据计算引擎中的任务往往会将数据处理结果或中间结果实时写入 LogHub,下游系统基于 LogHub 中的数据提供查询分析、监控告警、机器学习、迭代计算等能力。下图展示了面向 LogHub 的大数据处理系统架构图。
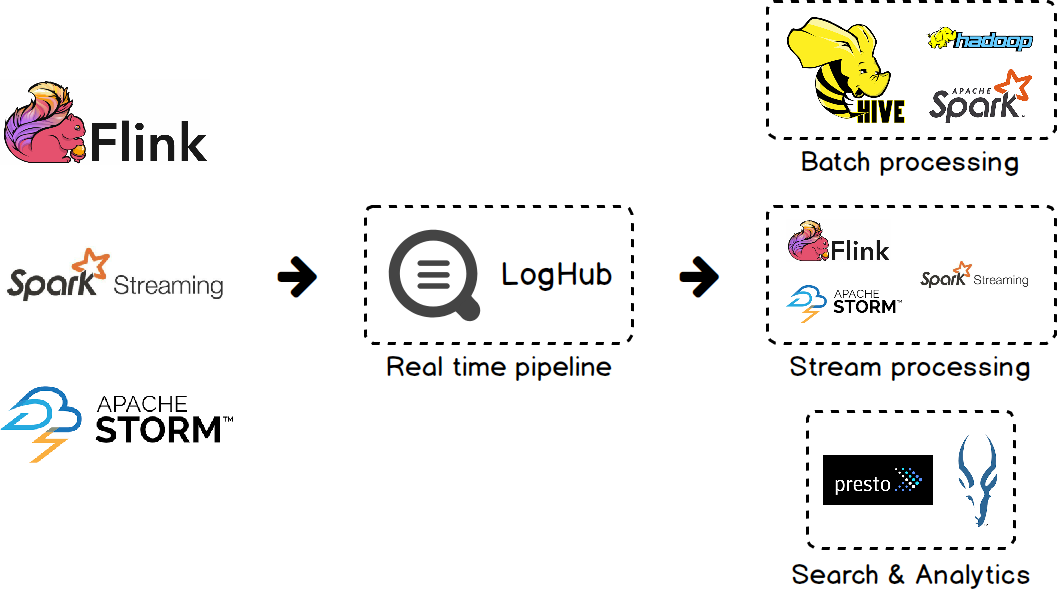
要让整个系统稳定地运行,提供便捷高效的数据写入手段是前提。直接使用 API 或 SDK 往往无法满足大数据场景下对数据写入能力的要求,在这样的背景下 应运而生。
功能特点
Aliyun LOG Java Producer 是一个易于使用且高度可配置的 Java 类库,它有如下功能特点:
- 线程安全 - producer 接口暴露的所有方法都是线程安全的。
- 异步发送 - 调用 producer 的发送接口通常能够立即返回。Producer 内部会缓存并合并发送数据,然后批量发送以提高吞吐量。
- 自动重试 - 对可重试的异常,producer 会根据用户配置的最大重试次数和重试退避时间进行重试。
- 行为追溯 - 用户通过 callback 或 future 不仅能获取当前数据是否发送成功的信息,还可以获得该数据每次被尝试发送的信息,有利于问题追溯和行为决策。
- 上下文还原 - 同一个 producer 实例产生的日志在同一上下文中,在服务端可以查看某条日志前后相关的日志。
- 优雅关闭 - 保证 close 方法退时,producer 缓存的所有数据都能被处理,用户也能得到相应的通知。
功能优势
使用 producer 相对于直接通过 API 或 SDK 向 LogHub 写数据会有如下优势。
高性能
在海量数据、资源有限的前提下,写入端要达到目标吞吐量需要实现复杂的控制逻辑,包括多线程、缓存策略、批量发送等,另外还要充分考虑失败重试的场景。Producer 实现了上述功能,在为您带来性能优势的同时简化了程序开发步骤。
异步非阻塞
在可用内存充足的前提下,producer 会对发往 LogHub 的数据进行缓存,因此用户调用 send 方法时能够立即返回,不会阻塞,达到计算与 I/O 逻辑分离的目的。稍后,用户可以通过返回的 future 对象或传入的 callback 获得数据发送的结果。
资源可控制
可以通过参数控制 producer 用于缓存待发送数据的内存大小,同时还可以配置用于执行数据发送任务的线程数量。这样做一方面避免了 producer 无限制地消耗资源,另一方面可以让您根据实际情况平衡资源消耗和写入吞吐量。
小结
综上所述,producer 在给您带来诸多优势的同时只暴露了简单的接口,为您屏蔽了复杂的底层细节;另外,您也无须担心它会影响到上层业务的正常运行,大大降低了数据接入门槛。
快速入门
Producer 的实现比较复杂,但使用起来却非常简单。想了解 producer 的正确打开方式请参考文章 。
原理剖析
为了让您更好地理解 producer 的表现行为,本章将带您探究它的实现原理,包括数据写入逻辑、核心组件的实现方式以及如何优雅地关闭 producer 中的各个组件。Producer 的整体架构如下图所示。
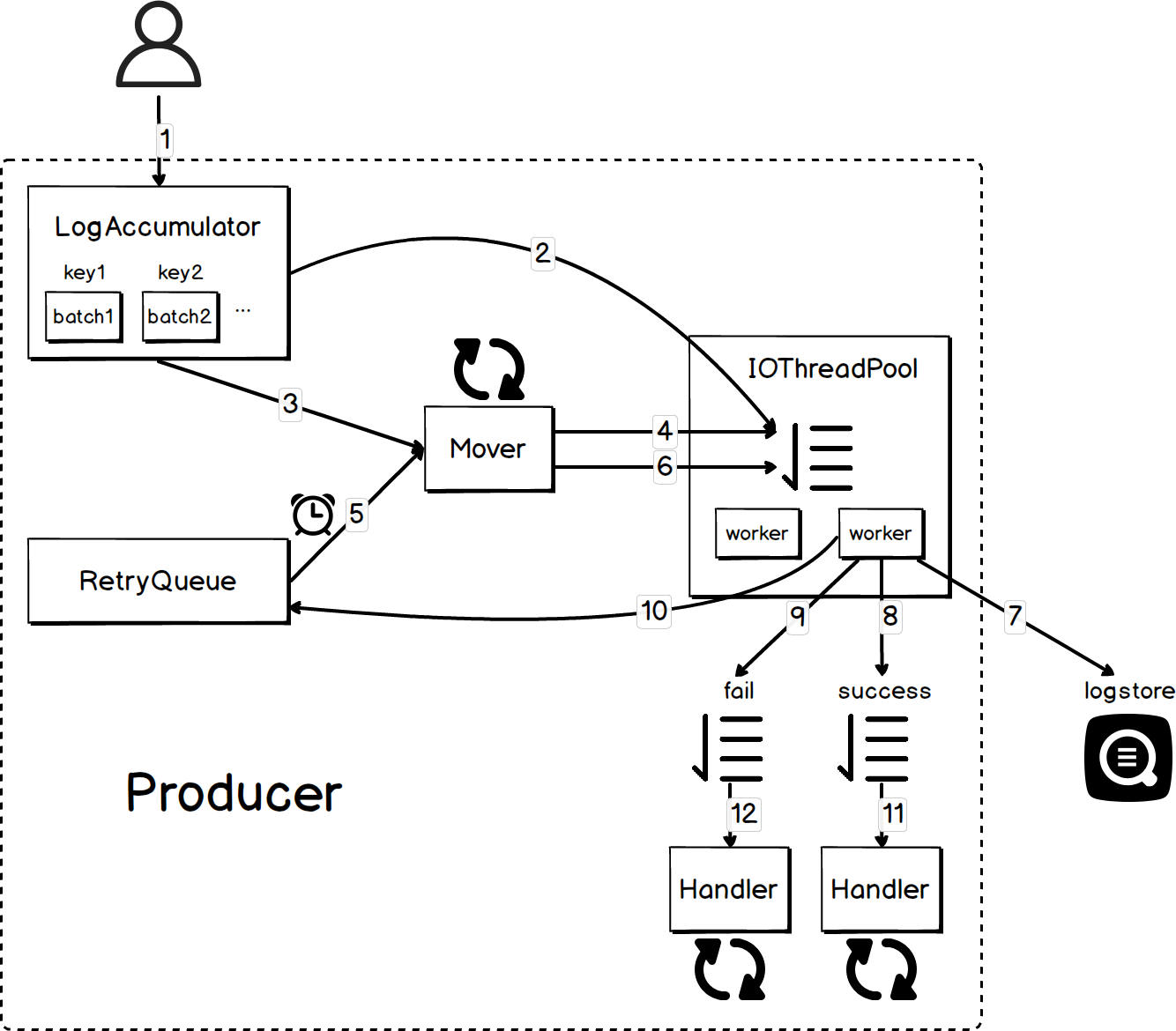
数据写入
Producer 的数据写入逻辑如下:
-
用户调用
producer.send()方法发送数据,数据会被加入到 LogAccumulator 中的某个 ProducerBatch 里。通常情况下 send 方法会立即返回,但如果该 producer 实例没有足够空间容纳当前数据,此方法会被阻塞直到下列任意一个条件被满足。- 之前缓存的数据被 BatchHandler 处理完成后,占用的内存被“释放”,producer 有足够空间容纳当前数据。
- 到达用户指定的最长阻塞时间,此时会抛出异常。
- 在调用 send 方法过程中,如果发现目标 ProducerBatch 包含的日志条数到达了 maxBatchCount 或该 ProducerBatch 剩余的空间无法容纳当前数据,则会首先将该 ProducerBatch 投递到 IOThreadPool 里,然后再新建一个 ProducerBatch 存放当前数据。为了不阻塞用户线程,IOThreadPool 选用无界阻塞队列,因为单个 Producer 实例能缓存的日志总大小是有限的,该队列长度不会无限增长。
- Mover 会遍历 LogAccumulator 中的每个 ProducerBatch,把超过了缓存时间的 batch 加入 expiredBatches 里。同时会记录未过期 batch 的最近超时时间,记为 t。
- 将从 LogAccumulator 中获取的 expiredBatches 投递到 IOThreadPool 里。
- 获取 RetryQueue 中所有满足发送条件的 ProducerBatch,如果当前没有 batch 满足发送条件则最多等待时间 t。
- 将从 RetryQueue 中获取的 expiredBatches 投递到 IOThreadPool 里。(Mover 完成步骤 6 后会再次进入步骤 3)。
- IOThreadPool 中的工作线程从阻塞队列里或取 ProducerBatch,然后发送给目标 logStore。
- 如果数据发送成功,会将该 ProducerBatch 写入成功队列。
-
如果数据发送失败,且满足下列任意一个条件,会将该 ProducerBatch 写入失败队列。
- 该错误无法重试。
- RetryQueue 被关闭。
- 达到了指定的重试次数且失败队列中的 batch 数不超过待发送 batch 总数的二分之一。
- 否则,计算当前 ProducerBatch 的下次计划发送时间然后将其放入 RetryQueue 中。
- 线程 SuccessBatchHandler 从成功队列里获取 batch,执行和该 batch 绑定的所有回调。
- 线程 FailureBatchHandler 从失败队列里获取 batch,执行和该 batch 绑定的所有回调。
核心组件
Producer 包含 、、、、、 等核心组件。
LogAccumulator
为了提高吞吐量,一个常见的做法是将若干个小包合并成大包批量发送,本小节介绍的 LogAccumulator 的主要作用便是合并待发送的数据。由于服务端要求具有相同 project、logstore、topic、source、shardHash 的数据才能组装成一个大包,LogAccumulator 会根据数据的这些属性将其缓存到内部 map 的不同位置。这个 map 的 key 为上述五元组,value 为 ProducerBatch。为了保证线程安全同时支持高并发,这里选用 ConcurrentMap 作为 map 的实现。
LogAccumulator 的另一个作用是控制缓存数据的总大小,这里选用 Semaphore 实现控制逻辑。Semaphore 是基于 AQS 实现的高性能同步工具,它会首先尝试通过自旋的方式获取共享资源,减少线程上下文切换的开销。
RetryQueue
RetryQueue 用于存放发送失败待重试的 ProducerBatch,每个 batch 有一个字段用于标识下次计划发送时间。为了高效地获取超时 batch,内部选用 DelayQueue 存放这些 batch。DelayQueue 是一种按时间排序的优先队列,最先超时的 batch 会被优先取出,同时它也是线程安全的。
Mover
Mover 是一个独立的线程,它会循环地将 LogAccumulator 和 RetryQueue 中的超时 batch 投递到 IOThreadPool 里。为了避免空转占用宝贵的 CPU 资源,当 Mover 发现 LogAccumulator 和 RetryQueue 里没有满足发送条件的 batch 时,会在 RetryQueue 的 expiredBatches 方法上等待用户配置的数据最长缓存时间 lingerMs。
IOThreadPool
IOThreadPool 中的工作线程用于真正执行数据发送任务,该线程池的大小可通过参数 ioThreadCount 指定,默认为可用处理器个数乘以 2。
SendProducerBatchTask
SendProducerBatchTask 封装了 batch 发送逻辑。为了避免阻塞 IO 线程,不论当前 batch 发送成功与否都会将其投递到队列中交由独立线程去执行回调。另外,如果某个发送失败的 batch 满足重试条件,不会在当前 IO 线程中立即重试(立即重试通常也会失败),而是根据指数退避策略将其投递到 RetryQueue 中。
BatchHandler
Producer 会启动一个 SuccessBatchHandler 和一个 FailureBatchHandler 分别用来处理发送成功或失败的 batch。Handler 在执行完 batch 的 callback、设置好 batch 的 future 后便会“释放”该 batch 占用的内存空间,供新的数据使用。分开处理的原因是为了隔离发送成功和发送失败的 batch,保持 producer 整体的流动性。
优雅关闭
要实现优雅关闭,需要做到以下几点:
- Close 方法在期望时间内返回时,producer 中的所有线程都应停止,缓存的数据都应得到处理,用户注册的 callback 都应被执行,返回给用户的 future 都应被设置。
- 支持用户设定 close 方法的最长等待时间,超过这个时间不论线程是否停止,缓存的数据是否完全处理,该方法都应立即返回。
- Close 方法支持被调用多次,在多线程环境下也能按预期工作。
- 在 callback 里调用 close 方法是安全的,不会造成程序死锁。
为了达到上述目标,producer 的关闭逻辑设计如下:
- 关闭 LogAccumulator,这时继续往 LogAccumulator 中写数据会抛异常。
- 关闭 RetryQueue,这时继续往 RetryQueue 中投递 batch 会抛异常。
- 关闭 Mover 并等待其完全退出。Mover 检测到关闭信号后会把 LogAccumulator 和 RetryQueue 中剩余的 batch 全部取出并投递到 IOThreadPool 中,不论它们是否满足发送条件。为了防止数据丢失,Mover 会不断从 LogAccumulator 和 RetryQueue 中获取 batch 直到没有其他线程正在写入。
- 关闭 IOThreadPool 并等待已提交的任务全部执行完毕。这时由于 RetryQueue 已经关闭,发送失败的 batch 会被直接投递到失败队列中。
- 关闭 SuccessBatchHandler 并等待其完全退出(如果检测到在 callback 里调用 close 方法会跳过等待过程)。SuccessBatchHandler 检测到关闭信号后会把成功队列中的 batch 全部取出并依次处理。
- 关闭 FailureBatchHandler 并等待其完全退出(如果检测到在 callback 里调用 close 方法会跳过等待过程)。FailureBatchHandler 检测到关闭信号后会把失败队列中的 batch 全部取出并依次处理。
可以看到,这里按照数据流动方向依次关闭队列和线程来达到优雅关闭、安全退出的目的。
总结
Aliyun LOG Java Producer 是对老版 producer 的全面升级,解决了上一版存在的多个问题,包括网络异常情况下 CPU 占用率过高、关闭 producer 可能出现少量数据丢失等问题。另外,在容错方面也进行了加强,就算用户使用不合理,在资源、吞吐、隔离上都有较好的保证。
技术支持

转载地址:http://hcgul.baihongyu.com/